About Me
AI with social-purpose. I work across fields in generative AI and sociotechnical foresight, to develop solutions for global challenges, equity and safety, participation and African AI leadership.

- Generative Machine Learning
- Weather & Climate
- Sociotechnical AI
- Transformation
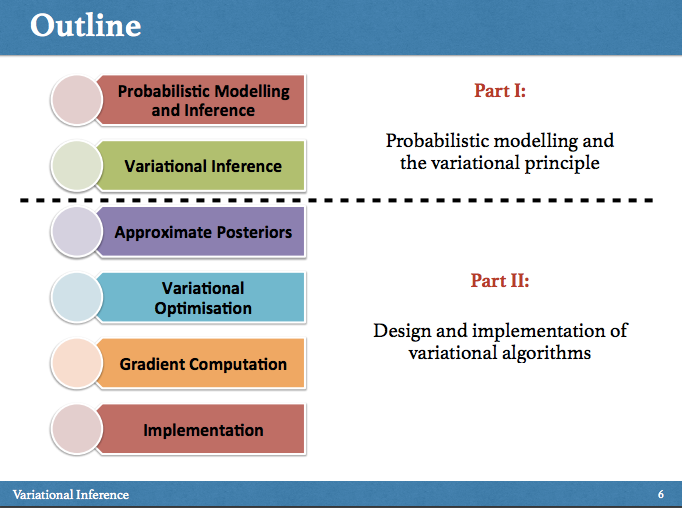
I am a scientist and engineer in the fields of statistical machine learning and artificial intelligence. I am most interested in research that combines multiple disciplines and views of machine learning and its applications. I shape my efforts around three conceptual pillars: Probabilistic Foundations of Learning and Intelligence, Addressing Global Challenges, and Transformation. I work towards developing methods focussed on probabilistic reasoning that lead to systems for agent-based decision-making. I work towards the application of machine learning to global challenges in healthcare and environment, and towards social Transformation that supports greater diversity, responsibility, and freedom. I love exploring and writing about the connections between different computational, epistemological, and social paradigms and maintain a blog at blog.shakirm.com.
I am a Director for research at Google DeepMind in London; I joined DeepMind as a small startup in 2013. I am also a founder and Chair of the Board of Trustees of the Deep Learning Indaba, a non-profit whose mission is to Strengthen African Machine Learning and Artificial Intelligence. I'm an Associate Fellow at the Leverhulme Centre for the Future of Intelligence at the University of Cambridge, and an Honorary Professor in the Department of Computer Science at University College London (UCL).
I was a programme chair for DALI2019, a programme co-chair for ICLR2019, the Senior Programme Chair for ICLR2020, the General Chair for ICLR2021, and a co-General Chair for NeurIPS 2022. I am a member of the Royal Society’s Diversity and Inclusion Committee (2020-2025). I am a member of the Board of Directors of ICML, ICLR, and NeurIPS.
Before moving to London, I held a Junior Research Fellowship from the Canadian Institute for Advanced Research (CIFAR) as part of the programme on Neural Computation and Adaptive Perception. I was based in Vancouver at the University of British Columbia in the Laboratory for Computational Intelligence (LCI) with Nando de Freitas. I completed my PhD with Zoubin Ghahramani at the University of Cambridge, where I was a Commonwealth Scholar to the United Kingdom and a member of St John’s College. I am from South Africa, and completed my previous degrees in Electrical and Information Engineering at the University of the Witwatersrand, Johannesburg.